
Designing Secure Autonomous AI Agents with Defense in Depth
AI agents are moving beyond assistance and into action. Instead of generating content, they invoke tools, modify data, trigger workflows, and operate across systems with increasing autonomy. This shift changes the security problem fundamentally. When an agent can act autonomously, mistakes propagate faster, blast radius increases, and rollback becomes harder.
Security for agentic AI relies on defense in depth. What changes with autonomous agentic AI is where security decisions matter most. As autonomy increases, the center of gravity moves away from the model alone and toward how agents are assembled, constrained, and governed inside real applications. To build agentic AI applications that can be operated safely at scale, you need to deliberately design how agents are assembled, constrained, and governed within real applications. In return, you increase the likelihood of predictable behavior, controlled blast radius, and the confidence to deploy autonomy in production.
Defense in depth for agentic AI systems
Agentic AI systems are vulnerable to the existing security risks of software systems, and introduce new threat classes: agent hijacking, intent breaking, sensitive data leakage, supply chain compromise, and inappropriate reliance. Any weakness in permissions, data protection, or access control that exists today is amplified when an agent is added to the system.
A useful way to reason about agent security is through the following mitigation layers:
- Model layer: Influences how the agent reasons through training data, fine-tuning, and refusal behaviors.
- Safety system layer: Provides runtime protections such as content filtering, guardrails, logging, and observability.
- Application layer: Defines what the agent can do and how it does it through application architecture, permissions, workflows, and escalation paths.
- Positioning layer: Shapes how the system is presented to users through transparency documentation and UX disclosure.
Each layer reinforces the others, and no single layer is sufficient on its own. The model layer is probabilistic by nature. The safety system layer observes and intervenes at runtime. The positioning layer shapes perception. But for organizations building agentic AI applications, the application layer is the decisive one because it is the only layer builders fully control. The application layer translates probabilistic model behavior into deterministic system outcomes. This is also where customers turn generic components into differentiated systems: two organizations can start with the same model and tools and end up with very different security outcomes depending on how they constrain agent behavior at this layer.
Why the application layer matters most when building agentic AI applications
Most organizations build agentic AI applications by combining off-the-shelf models, tools, and business data into systems that perform specific tasks. The application layer is where they decide which actions an agent is allowed to take, which tools and data it can access, how permissions are scoped and enforced, how failures are handled, and when humans must be involved.
Getting these decisions right requires thinking through several specific design patterns. Each one addresses a distinct failure mode. Together, they form the practical expression of defense in depth at the application layer.
Here are some recommended design patterns for building a more resilient application layer for your agents.
Pattern 1: Design agents like microservices
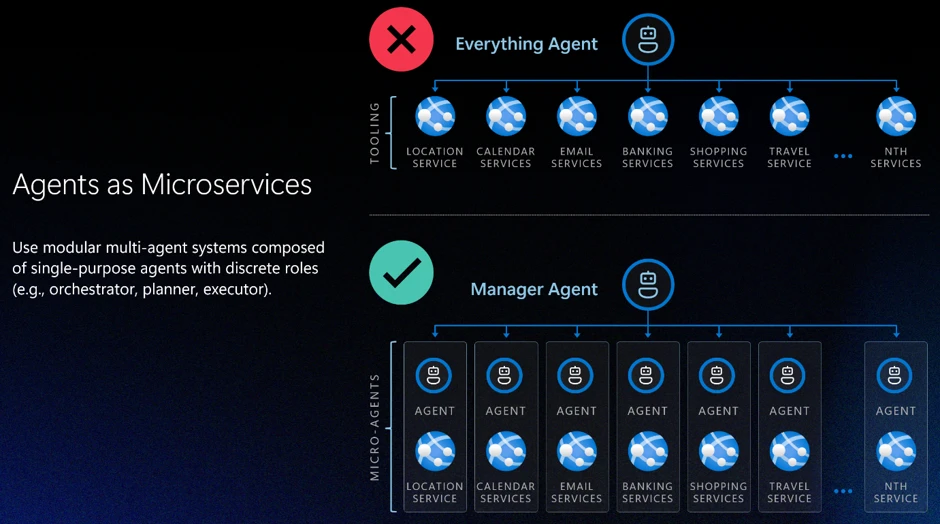
The most consequential application layer decision is action scope: how broadly you define an agent’s responsibilities. A common and dangerous failure mode is the “everything agent,” a single agent with broad permissions, many tools, and loosely defined responsibilities. Every additional tool expands the attack surface. Every ambiguous instruction increases the risk of error or task drift. As autonomy and tools increase, these risks compound quickly.
A more resilient approach is to design agents the way distributed systems have been designed for decades: as carefully scoped components with bounded capabilities. Agents should have isolated permissions, clear interfaces, and narrow responsibilities. More complex behaviors emerge from orchestration rather than from granting a single agent broad authority. Building agents like microservices, with constrained responsibilities and scoped permissions by design, is one of the most effective structural controls available at the application layer.
Pattern 2: Least permissions
Bounded scope defines what an agent is responsible for. Progressive permissioning governs what actions are permitted within that scope. As a rule, permissions should always start at zero (“zero trust”).
For safe design, no actions should be permitted by default. Actions are enabled explicitly, based on role and system needs. Least-privilege and zero-access principles apply to agents just as they do to human users.
Permissions granted loosely at design time become exploitable surfaces at runtime.
In practice, this means every tool call, data access, and external integration an agent can invoke should be the result of a deliberate authorization decision, not an implicit one. The question is not “should we restrict this?” but “have we explicitly permitted this?”
The general rule is to scope capabilities to the duration of a specific task. If task-based limits aren’t feasible, implement time-based limits. Task-focused permissions are preferred because they naturally “expire” when the task completes; temporal permissions help limit blast radius.
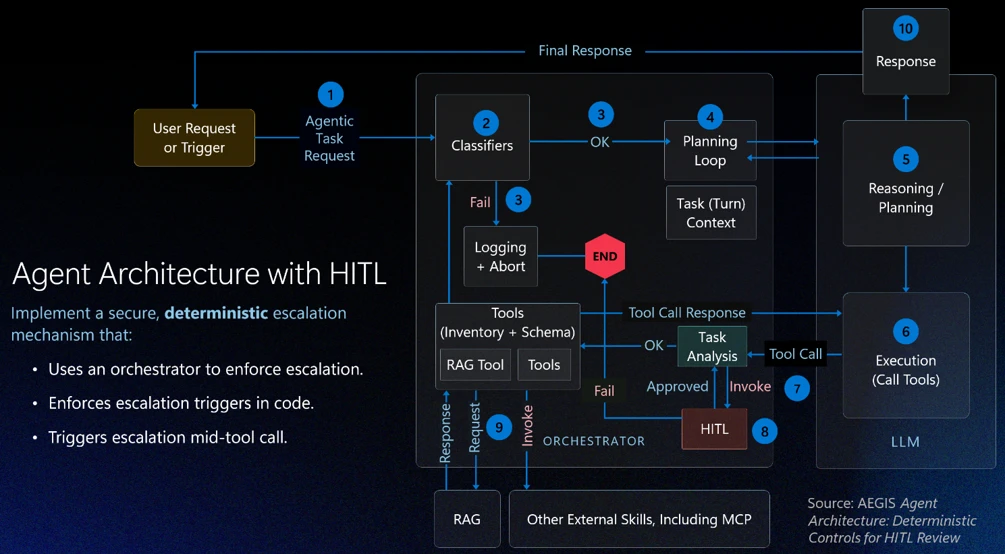
Pattern 3: Deterministic human-in-the-loop design
Even well-scoped, well-permissioned agents need a governance backstop for high-stakes decisions. Human-in-the-loop (HITL) review is often discussed as a trust mechanism: a way to keep humans informed. In agentic systems, it is better understood as a governance mechanism: a structural control that prevents agents from self-authorizing consequential actions.
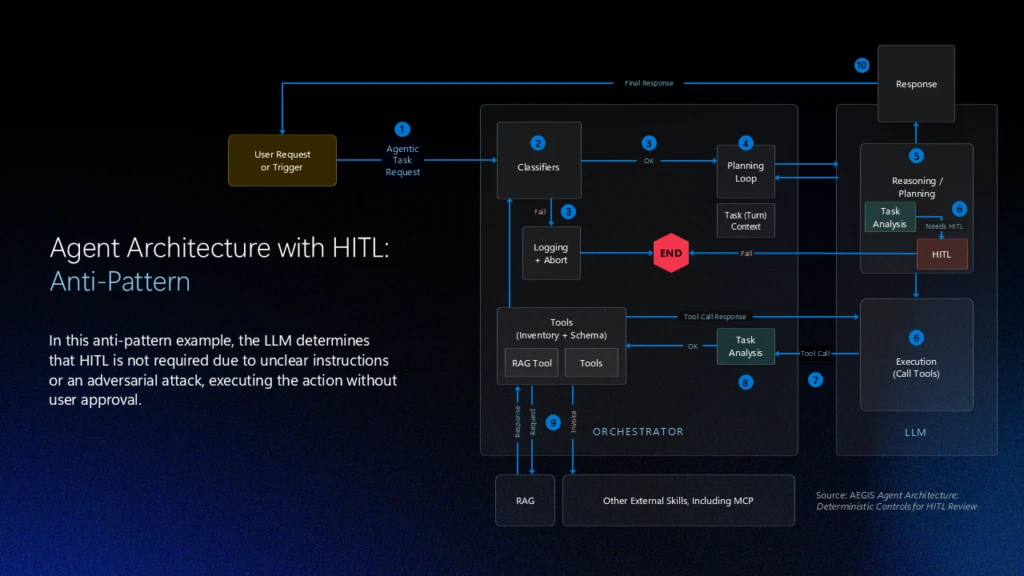
The critical design mistake here is letting the model decide when human review is required. If escalation is left to probabilistic reasoning, an adversarial prompt or an ambiguous instruction can bypass review entirely. A model that reasons its way out of escalating is exhibiting exactly the behavior the escalation mechanism was supposed to catch.
In secure agentic systems:
- HITL review ideally is enforced deterministically by the application layer, or orchestrator, not delegated to the model.
- Escalation triggers are defined in code.
- An orchestrator enforces HITL review triggers.
- Intervention can occur mid-execution — including during tool calls — rather than only before or after an action completes.
This design removes ambiguity about when review is required, supports auditability for oversight and compliance, and ensures that as agents move toward greater autonomy, the separation between reasoning and enforcement remains intact.
Pattern 4: Agent identity as a security primitive
It is an unfortunate reality that human users are routinely over-permissioned (“give them access to everything”). To implement Pattern 1: Agents as Microservices and Pattern 2: Least permissions, agents must never have the same identity as the user. This sounds obvious, but it requires deliberate design: When an action is taken, you need to know if it was executed by the user, the agent was acting on its own behalf, or the agent acting on the user’s behalf. Each agent must be assigned a unique, verifiable identity which allows assignment of explicit and narrowly scoped permissions, lifecycle controls, and accountability.
Agent identity enables least-privilege enforcement, because you cannot scope permissions to a specific agent if you cannot distinguish that agent from other agents or a human user. It also enables lifecycle governance, because revocation actions won’t be invoked when many agents are affected. Finally, separate agent identity enables meaningful observability, because actions can be traced back to a specific agent rather than being attributed vaguely to “the system.”
As enterprises manage agent sprawl (with more agents, more deployments, and even more integrations), identity clarity becomes operationally critical. Identity is not a feature you add later. It is a prerequisite for operating autonomous agents responsibly at scale, and it ties together every other application layer pattern: permissioning, escalation, and logging all depend on knowing which agent is acting.
How the Other Layers Reinforce Application‑Layer Design
Focusing on the application layer does not diminish the importance of the other layers. Instead, it clarifies their roles.
- The model layer – the model chosen to enable the application – shapes how an agent reasons, but remains probabilistic. It can be tuned toward safer behavior, but it cannot guarantee it.
- The safety system layer – platform tools like content filters and groundedness detection – compensates for what models alone cannot prevent: it detects anomalies, filters harmful outputs, and fulfills the observability teams’ need to respond when something goes wrong.
- The positioning layer – how the UI and UX explains that AI is in use, what it can do, and what it can’t do
Each layer addresses failure modes the others cannot fully cover. A strong safety system cannot compensate for an agent with unlimited scope. A well-tuned model cannot substitute for deterministic escalation triggers. The application layer is where the load-bearing decisions are made. The other layers make those decisions more resilient.
Designing for Secure Autonomy
The four patterns described here — agents as microservices, least permissions, deterministic human-in-the-loop design, and agent identity — are mutually reinforcing. Scope containment limits blast radius. Permissioning limits what a contained agent can do. Deterministic escalation ensures that neither scope nor permissions can be circumvented by adversarial input. Identity makes all of it auditable.
The application layer is where customers have the most power to shape how their agent behaves. It is where off‑the‑shelf models become real agentic AI applications. It is where security decisions shape both business value and risk. Defense in depth remains the right strategy. As agents take on more responsibility, the application layer becomes the place where that strategy succeeds or fails.
As organizations deploy more agentic AI systems, the question is not whether agents will make mistakes. They already have and will continue to. The question is whether those mistakes are minimized, identified, and contained. Secure autonomous agentic AI systems are achieved by designing systems where autonomy is bounded by architecture, permissions, identity, and deterministic oversight from the start.
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.
The post Defense in depth for autonomous AI agents appeared first on Microsoft Security Blog.
